存储
存储项目全解析
如果我们要为互联网的去中心化铺平道路,我们最终会集中在三个支柱上:共识、存储和计算。如果人类成功地将这三者去中心化,我们将完全实现互联网的下一个迭代:Web3。
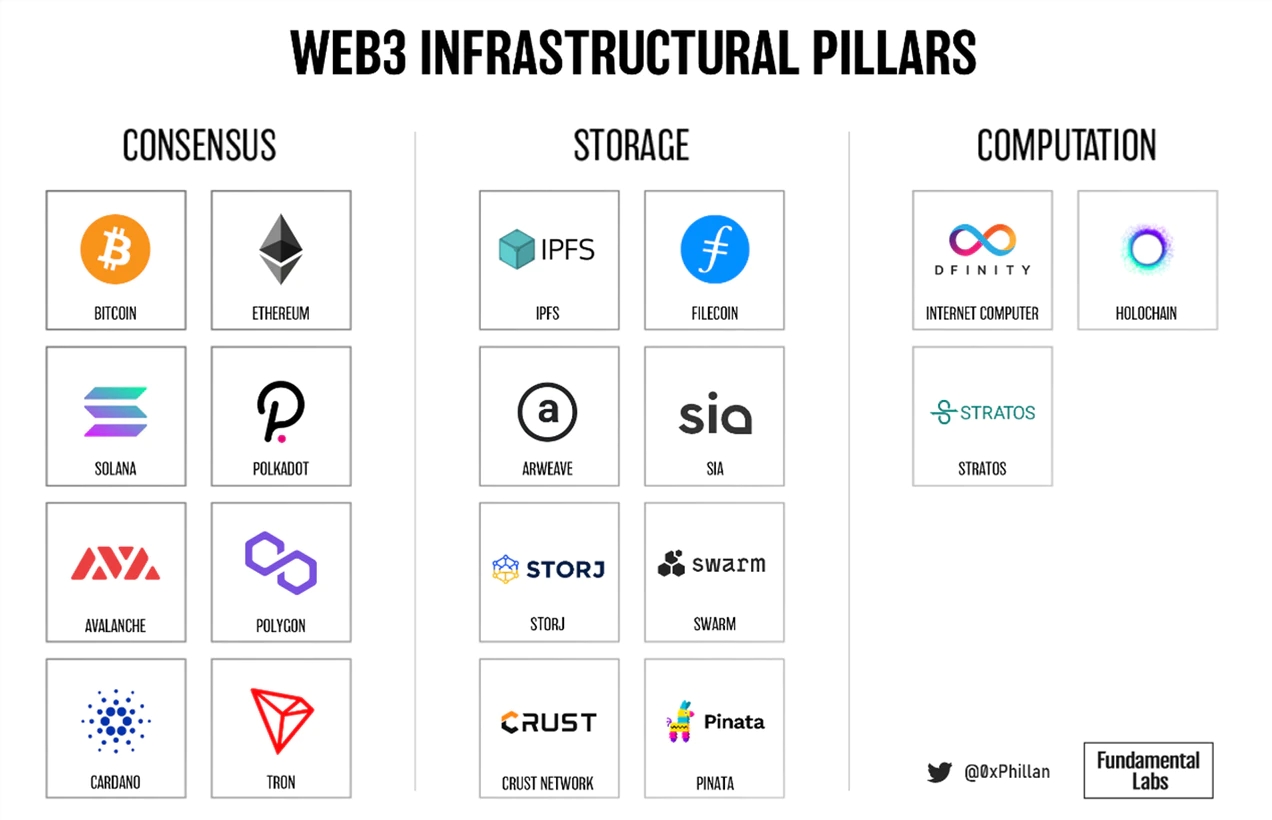
(Web3基础板块:共识、存储、计算)
存储是第二个支柱,它正在迅速成熟,出现了适合特定用例的各种存储解决方案。在这篇文章中,我们将仔细研究去中心化存储支柱。
去中心化存储的需求
从区块链的角度来看,我们需要去中心化存储,因为区块链本身并不是为存储大量数据而设计的。用于实现区块链共识的机制依赖于以区块排列的少量数据,并且这些数据在网络中快速共享以由节点验证。
首先,在这些块中存储数据非常昂贵。在撰写本文时,将BAYC#3368的整个图像数据直接存储在第1层网络上的成本可能超过18,000美元。
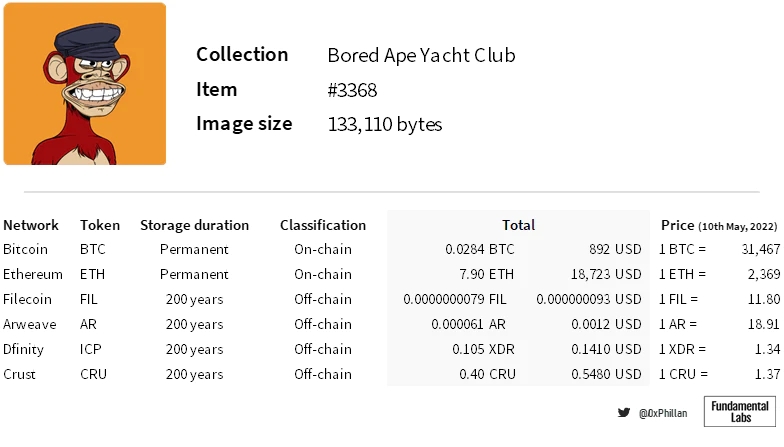
(具有活跃主网的项目。选择200年的存储期限以符合Arweave对永久性的定义。来源:网络文档、Arweave存储计算器)
其次,如果我们在这些区块中存储大量任意数据,网络拥塞将严重增加,从而导致用户通过gas竞价使用网络的价格上涨。这是区块隐含时间价值的结果——如果用户需要在特定时间向网络提交交易,他们将支付更多的gas费用以使其交易优先。
因此,建议将NFT的底层元数据和图像数据以及dApp前端存储在链下。
中心化网络的考察
如果在区块链上存储数据如此昂贵,为什么不将链下数据存储在中心化网络上呢?
原因是:中心化网络容易受到审查并且是可变的。他们要求用户信任存储提供商以确保数据安全。不能保证中心化网络的运营商能够不辜负信任:因为数据可能会被故意或意外删除,(例如由于存储提供商的政策变化、硬件故障或受到第三方攻击派对)。
NFT
由于某些NFT收藏的底价超过10万美元,而某些收藏的每kb图像数据价值高达7万美元,因此承诺不足以确保数据始终可用。需要更强的保证来确保底层NFT数据的不变性和永久性。
(珍贵NFT的价值,数据截止5.10/2022)
NFT本身实际上并不包含任何图像数据,而是包含指向存储在链下的元数据和图像数据的指针。需要保护的正是这些元数据和图像数据,好像它消失了一样,NFT将只是一个空容器。
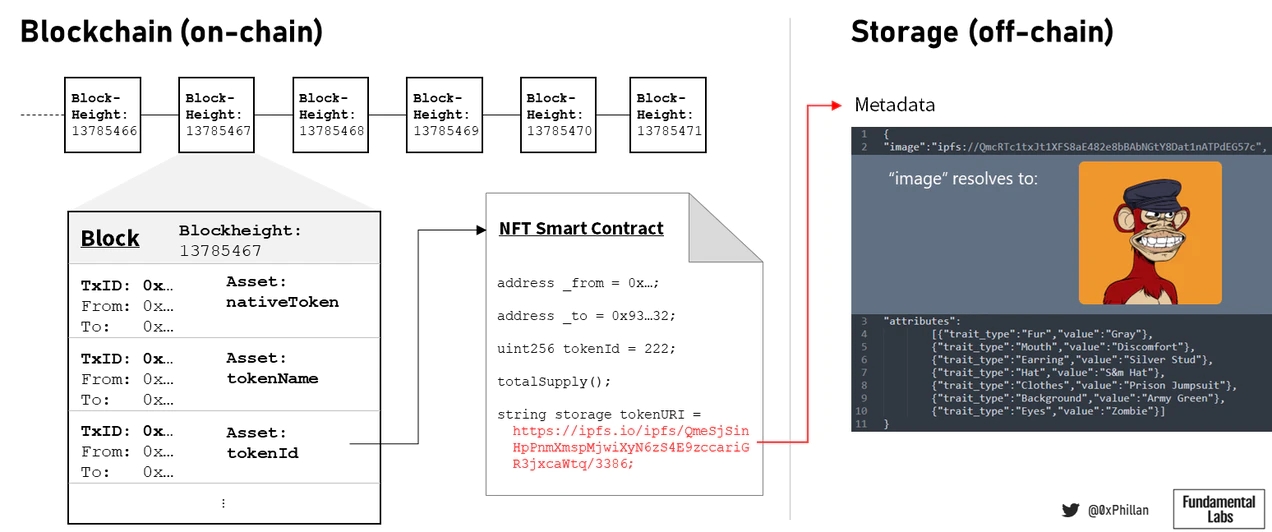
(区块链、区块、NFT和链下元数据)
NFT的价值主要不是由它们所指的元数据和图像数据驱动,而是由围绕其收藏价值和生态系统的社区驱动。虽然这可能是正确的,但如果没有基础数据,NFT将没有意义,社区也就无法形成。
除了个人资料图片和艺术收藏品,NFT还可以代表现实世界资产的所有权(例如房地产或金融工具)。此类数据具有外在的现实世界价值,并且由于它所代表的内容,保存作为NFT基础的每个数据字节至少与链上NFT一样有价值。
dApp
如果NFT是存在于区块链上的商品,那么dApp可以被认为是存在于区块链上并促进与区块链交互的服务。dApp是存在于链下的前端用户界面和存在于网络上并与区块链交互的智能合约的组合。有时它们也有一个简单的后端,可以将某些计算移出链,以减少所需的gas,从而减少最终用户对某些交易产生的成本。
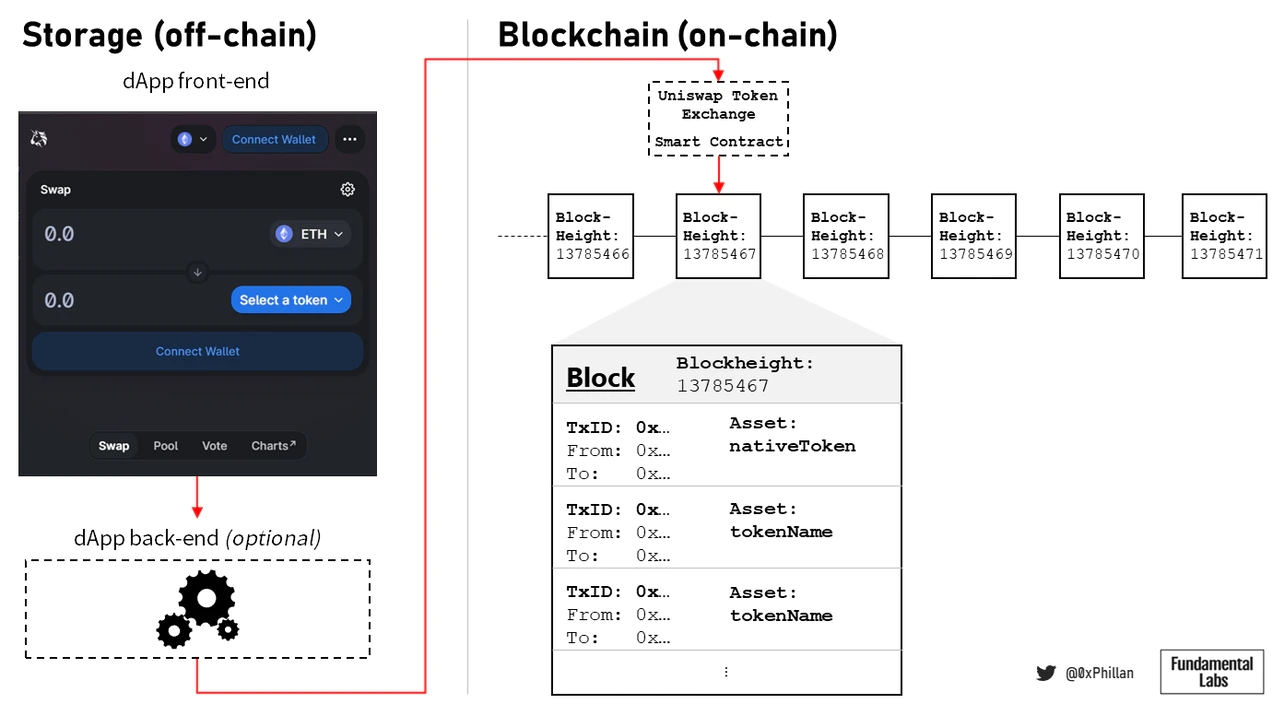
(dApp与区块链交互)
虽然dApp的价值应该在dApp的目的(例如,DeFi、GameFi、社交、元节、名称服务等)的背景下考虑,但dApp促进的价值量是惊人的。DappRadar上排名前10位的dApp在过去30天内共同促成了超过1500亿美元的转账。
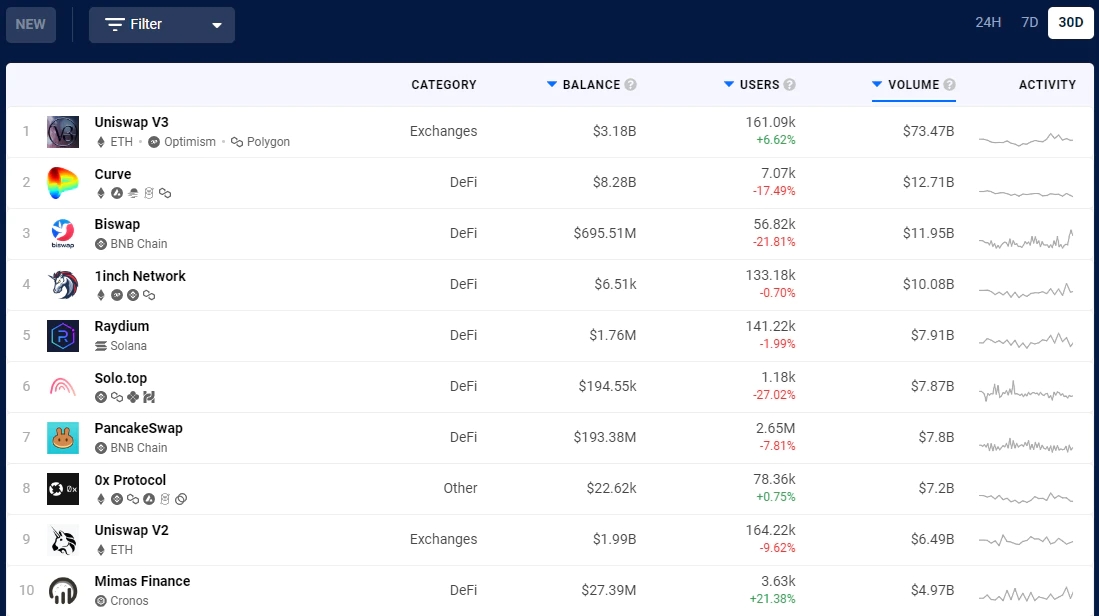
(数据来源:DappRadar,截止5.11/2022)
尽管dApp的核心机制是通过智能合约执行的,但最终用户的可访问性是通过其前端来确保的。因此,从某种意义上说,确保dApp前端的可用性就是确保底层服务的可用性。
去中心化存储降低了服务器故障、DNS黑客攻击或中心化实体移除对dApp前端的访问权限的可能性。即使dApp的开发停止,前端和通过该前端访问智能合约的权限也可以继续存在。
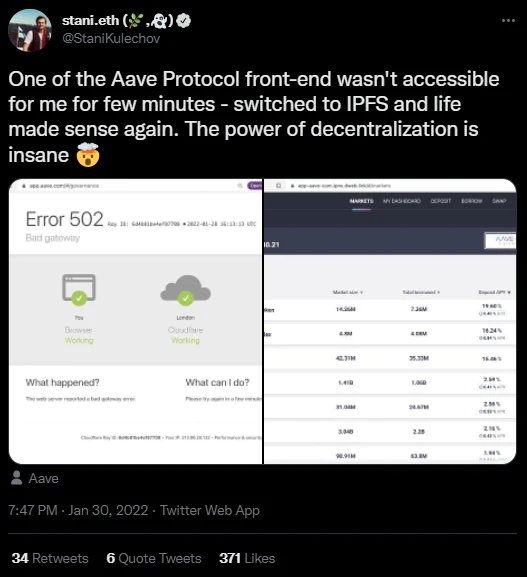
(Aave创始人Stani Kulechov在推特上表示,Aave dApp前端于2022年1月20日下线,但仍可通过IPFS托管的网站副本访问)
去中心化存储环境
比特币和以太坊等区块链的存在主要是为了促进价值转移。当涉及到去中心化存储网络时,一些网络也采用了这种方法:它们使用原生区块链来记录和跟踪存储订单,这代表了价值转移以换取存储服务。然而,这只是众多潜在方法中的一种——存储领域广阔,多年来出现了具有不同权衡和用例的不同解决方案。
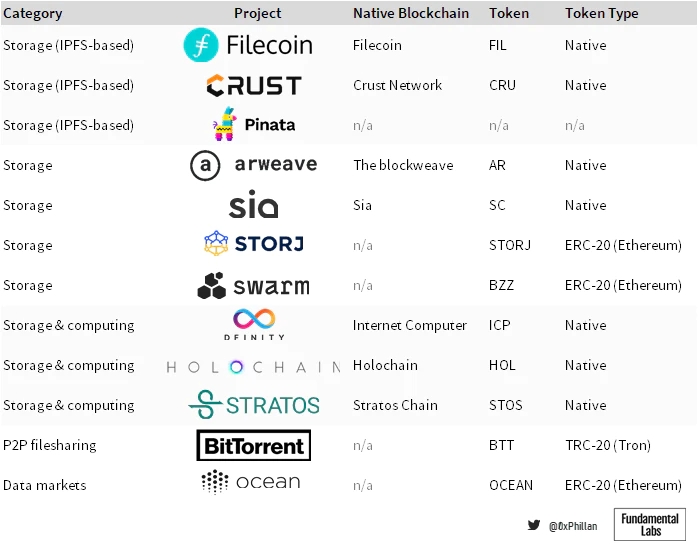
(部分涉及去中心化存储的协议)
尽管存在许多差异,但上述所有项目都有一个共同点:这些网络都没有在所有节点上复制所有数据。在去中心化存储网络中,存储数据的不变性和可用性不是通过大多数网络存储所有数据并验证连续链接的数据来实现的。尽管如前所述,许多网络选择使用区块链来跟踪存储订单。
让去中心化存储网络上的所有节点都存储所有数据是不可持续的,因为运行网络的间接成本会迅速提高用户的存储成本,并最终推动网络向少数能够负担得起硬件的节点运营商更加中心化。因此,去中心化存储网络需要克服非常不同的挑战。
数据去中心化的挑战
回顾前面提到的关于链上数据存储的限制,很明显去中心化存储网络必须以不影响网络价值转移机制的方式存储数据,同时确保数据保持持久性、不可变性和可访问性。从本质上讲,去中心化存储网络必须能够存储数据、检索数据和维护数据,同时确保网络中的所有参与者都受到他们所做的存储和检索工作的激励,同时还要维护去中心化系统的去信任化。
这些挑战可以总结为以下问题:
●数据存储格式:存储完整文件还是文件片段?
●数据复制:跨多少个节点存储数据(完整文件或片段)?
●存储跟踪:网络如何知道从哪里检索文件?
●数据存储证明:节点是否存储了他们被要求存储的数据?
●随时间推移的数据可用性:数据是否仍随时间推移而存储?
●存储价格发现:存储成本如何确定?
●持久数据冗余:如果节点离开网络,网络如何确保数据仍然可用?
●数据传输:网络带宽是有代价的——如何确保节点在被询问时检索数据?
●网络代币经济学:除了确保数据在网络上可用之外,网络如何确保网络长期存在?
作为本次研究的一部分,已探索的各种网络采用了广泛的机制,并通过某些权衡来实现去中心化。
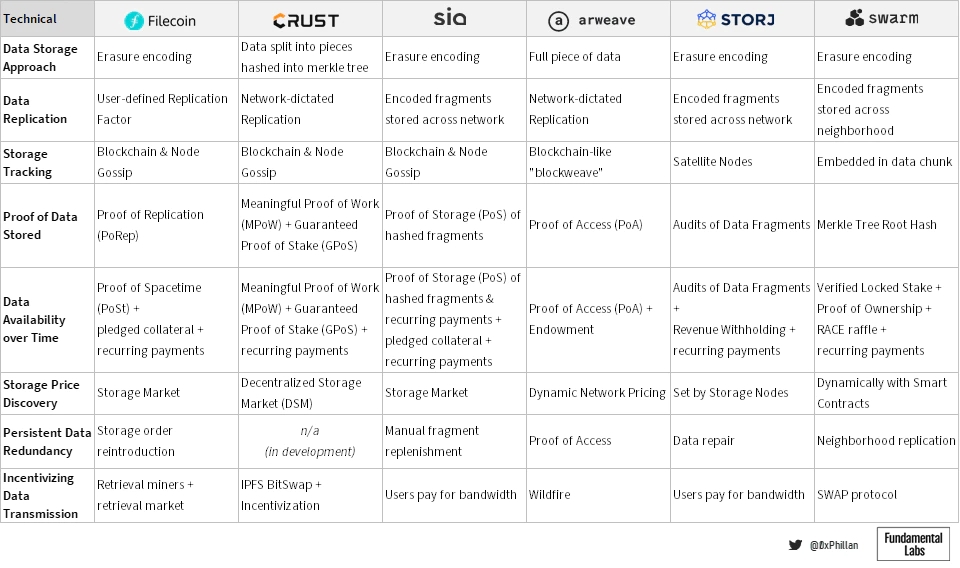
(对比去中心化存储网络的技术设计)
数据存储格式
在这些网络中,有两种主要的方法用于在网络上存储数据:存储完整文件和使用纠删码:Arweave和Crust Network存储完整文件,而Filecoin、Sia、Storj和Swarm都使用纠删码。在擦除编码中,数据被分解成大小恒定的片段,每个片段都被扩展并使用冗余数据进行编码。保存到每个片段中的冗余数据使得只需要片段的一个子集来重建原始文件。
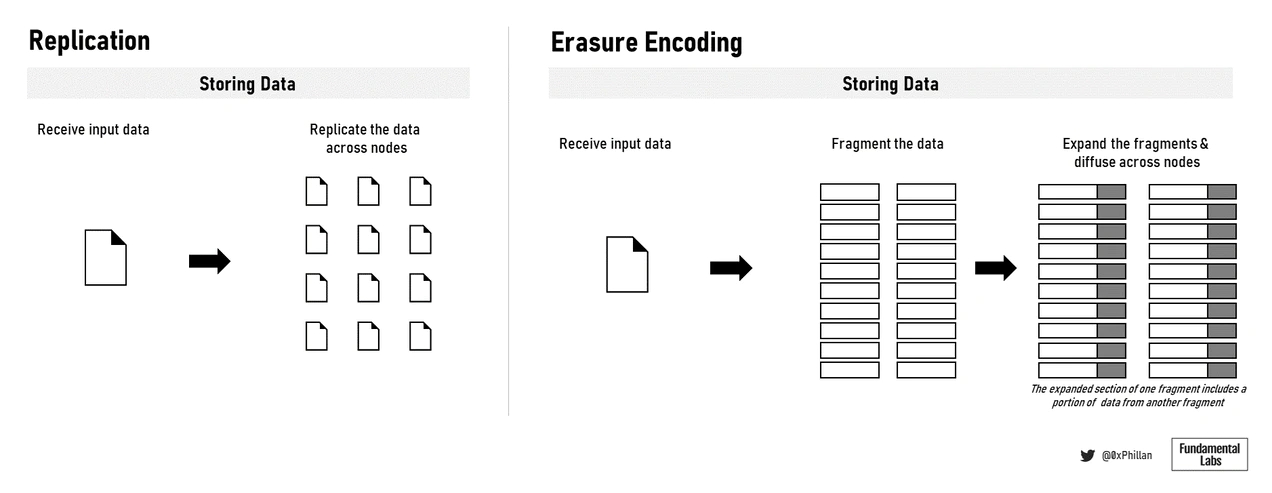
(数据的数据复制和擦除编码)
数据复制
在Filecoin、Sia、Storj和Swarm中,网络确定擦除编码片段的数量以及要存储在每个片段中的冗余数据的范围。然而,Filecoin还允许用户确定复制因子,该因子决定了作为与单个存储矿工的存储交易的一部分,应该在多少个单独的物理设备上复制擦除编码片段。如果用户想用不同的存储矿工存储文件,那么用户必须进行单独的存储交易。Crust和Arweave让网络决定复制,而在Crust上手动设置复制因子是可能的。在Arweave上,存储证明机制激励节点存储尽可能多的数据。因此,Arweave的复制上限是网络上存储节点的总数。
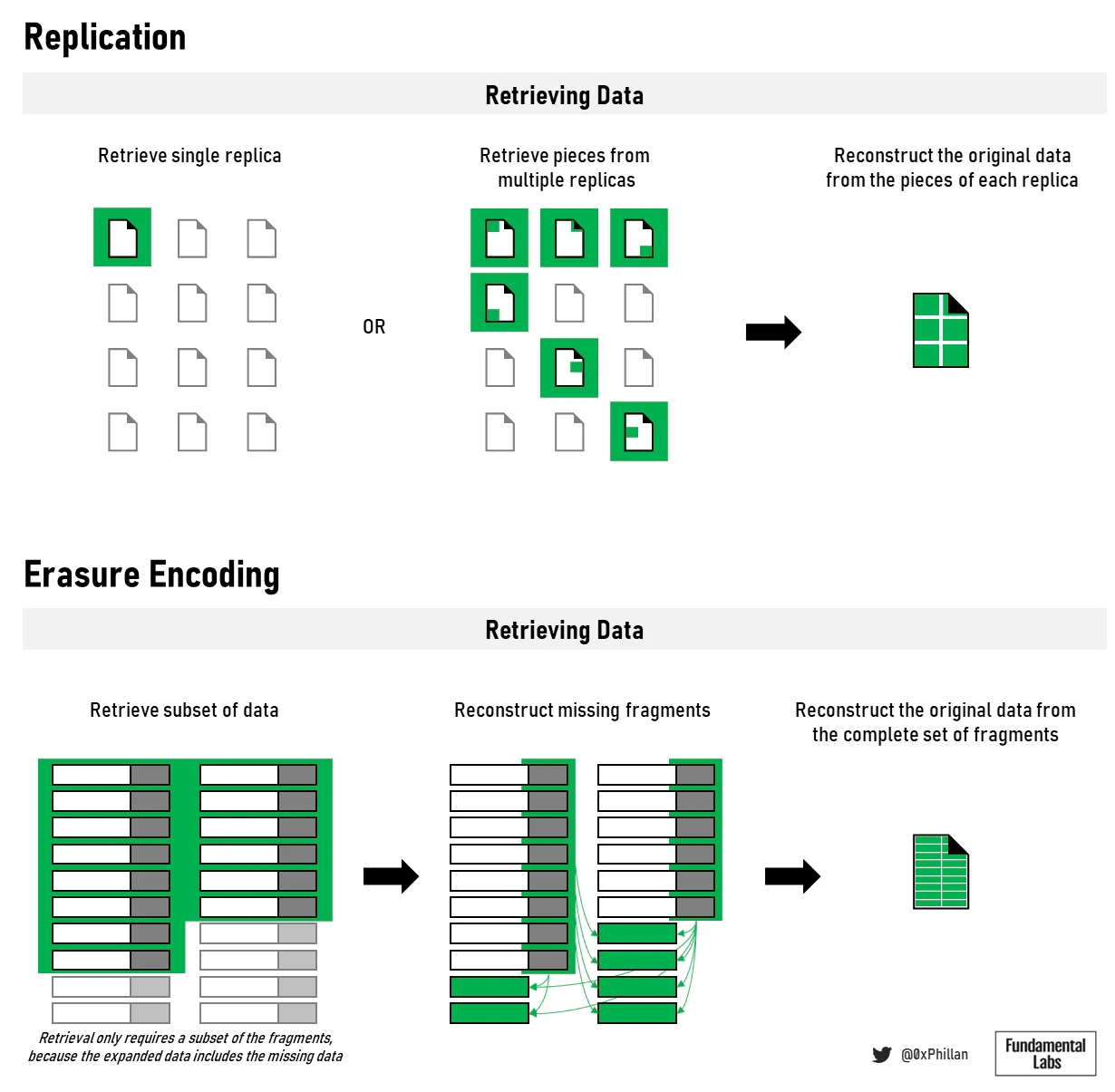
(数据存储格式将影响检索和重建)
用于存储和复制数据的方法将影响网络检索数据的方式。
存储跟踪
在数据以网络存储它的任何形式分布在网络中的节点之后,网络需要能够跟踪存储的数据。Filecoin、Crust和Sia都使用本地区块链来跟踪存储订单,而存储节点还维护本地网络位置列表。Arweave使用类似区块链的结构。与比特币和以太坊等区块链不同,在Arweave上,节点可以自行决定是否存储块中的数据。因此,如果比较Arweave上多个节点的链,它们将不完全相同——相反,某些节点上的某些块会丢失,而在其他节点上可以找到。
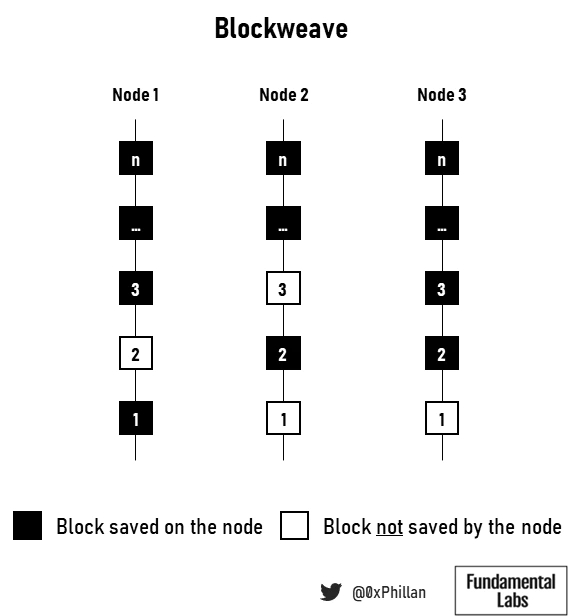
(Arweave网络-blockweave中三个节点的图示)
最后,Storj和Swarm使用了两种完全不同的方法。在Storj中,称为卫星节点的第二种节点类型充当一组存储节点的协调器,这些节点管理和跟踪数据的存储位置。在Swarm中,数据的地址直接嵌入到数据块中。检索数据时,网络根据数据本身知道在哪里查找。
存储数据的证明
在证明数据的存储方式时,每个网络都采用自己独特的方法。Filecoin使用复制证明——一种专有的存储证明机制,它首先将数据存储在存储节点上,然后将数据密封在一个扇区中。密封过程使得相同数据的两个复制片段可以证明彼此是唯一的,从而确保正确数量的副本存储在网络上(因此,“复制证明”)。
Crust将一段数据分解成许多小块,这些小块被散列到Merkle树中。通过将存储在物理存储设备上的单个数据的散列结果与预期的Merkle树散列进行比较,Crust可以验证文件是否已正确存储。这类似于Sia的方法,不同之处在于Crust将整个文件存储在每个节点上,而Sia存储擦除编码的片段。Crust可以将整个文件存储在单个节点上,并且仍然可以通过使用节点可信执行环境(TEE)来实现隐私,这是一个即使硬件所有者也无法访问的密封硬件组件。Crust将此存储算法证明称为“有意义的工作证明”,而有意义的表示仅在对存储的数据进行更改时才计算新的哈希值,从而减少无意义的操作。Crust和Sia都将Merkle树根哈希存储在区块链上,作为验证数据完整性的真实来源。
Storj通过数据审计检查数据是否已正确存储。数据审计类似于Crust和Sia如何使用Merkle树来验证数据片段。在Storj上,一旦有足够的节点返回了他们的审计结果,网络就可以根据多数响应确定哪些节点有故障,而不是与区块链的事实来源进行比较。Storj中的这种机制是有意的,因为开发人员认为,通过区块链减少网络范围内的协调可以在速度(无需等待共识)和带宽使用(无需整个网络定期与区块链)。
Arweave使用加密工作证明难题来确定文件是否已存储。在这种机制中,为了让节点能够挖掘下一个块,他们需要证明他们可以访问前一个块和来自网络块历史的另一个随机块。因为在Arweave中,上传的数据直接存储在块中,证明对前一个块的访问证明存储提供者确实正确保存了文件。
最后,在Swarm上也使用Merkle树,不同之处在于Merkle树不用于确定文件位置,而是将数据块直接存储在Merkle树中。在swarm上存储数据时,树的根哈希(也是存储数据的地址)证明文件已正确分块和存储。
随时间推移的数据可用性
同样,在确定数据是否存储在特定时间段内时,每个网络都使用独特的方法。在Filecoin中,为了减少网络带宽,存储矿工需要在要存储数据的时间段内连续运行复制证明算法。每个时间段的结果哈希证明在特定时间段内存储空间已被正确的数据占用,因此是“时空证明”。
Crust、Sia和Storj定期对随机数据片段进行验证,并将结果报告给他们的协调机制——Crust和Sia的区块链,以及Storj的卫星节点。Arweave通过其访问证明机制确保数据的一致可用性,这要求矿工不仅要证明他们可以访问最后一个块,还要证明他们可以访问一个随机的历史块。存储较旧和稀有的区块是一种激励措施,因为这增加了矿工赢得工作量证明难题的可能性,该难题是访问特定区块的先决条件。
另一方面,Swarm定期运行抽奖活动,奖励节点随着时间的推移持有不那么受欢迎的数据,同时还为节点承诺在更长时间内存储的数据运行所有权证明算法。
Filecoin、Sia和Crust需要节点存入抵押品才能成为存储节点,而Swarm只需要它用于长期存储请求。Storj不需要前期抵押品,但Storj将代扣矿工的部分存储收入。最后,所有网络在节点可证明存储数据的时间段内定期向节点付款。
存储价格发现
为了确定存储价格,Filecoin和Sia使用存储市场,存储供应商设定他们的要价,存储用户设定他们愿意支付的价格,以及其他一些设置。然后,存储市场将用户与满足其要求的存储提供商联系起来。Storj采用了类似的方法,主要区别在于没有一个单一的网络范围的市场可以连接网络上的所有节点。相反,每颗卫星都有自己的一组与之交互的存储节点。
最后,Crust、Arweave和Swarm都让协议决定了存储的价格。Crust和Swarm允许根据用户的文件存储要求进行某些设置,而在Arweave上文件始终是永久存储的。
持久数据冗余
随着时间的推移,节点将离开这些开放的公共网络,当节点消失时,它们存储的数据也会消失。因此,网络必须积极地在系统中保持一定程度的冗余。Sia和Storj通过收集片段子集、重建基础数据然后重新编码文件以重新创建丢失的片段来补充丢失的擦除编码片段来实现这一点。在Sia中,用户必须定期登录Sia客户端才能进行碎片补充,因为只有客户端才能区分哪些数据碎片属于哪条数据和用户。在Storj上,Satellite负责始终在线并定期运行数据审计以补充数据片段。
Arweave的访问证明算法确保数据始终在整个网络中定期复制,而在Swarm上,数据被复制到彼此靠近的节点。在Filecoin上,如果数据随着时间的推移而消失并且剩余的文件碎片低于某个阈值,则存储订单将重新引入存储市场,允许另一个存储矿工接管该存储订单。最后,Crust的补货机制目前正在开发中。
激励数据传输
随着时间的推移,数据被安全存储后,用户会想要检索数据。由于带宽是有代价的,因此必须激励存储节点在需要时提供数据。Crust和Swarm使用债务和信用机制,其中每个节点跟踪它们的入站和出站流量如何与它们与之交互的其他节点进行交互。如果一个节点只接受入站流量,但不接受出站流量,则它将被取消优先级以供将来通信,这可能会影响其接受新存储订单的能力。Crust使用IFPS Bitswap机制,而Swarm使用名为SWAP的专有协议。在Swarm的SWAP协议上,网络允许节点用邮票来偿还他们的债务(只接受没有足够出站流量的入站流量),这可以兑换他们的实用代币。
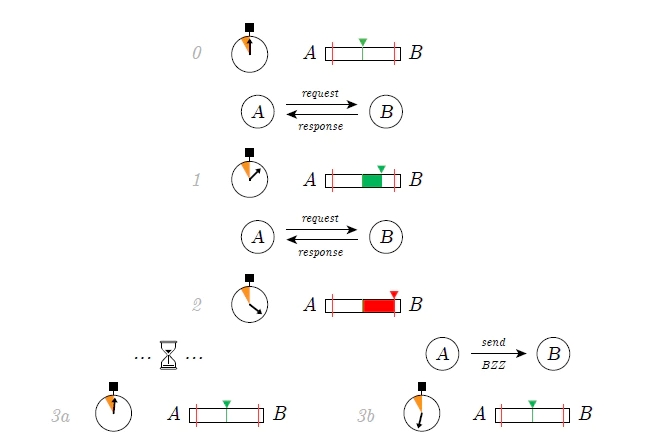
群记帐协议(SWAP)
这种对节点慷慨的跟踪也是Arweave确保数据在请求时传输的方式。在Arweave中,这种机制称为野火,节点将优先考虑排名更好的对等节点,并相应地合理化带宽使用。最后,在Filecoin、Storj和Sia上,用户最终会为带宽付费,从而激励节点在请求时交付数据。
代币经济学
代币经济学设计确保了网络的稳定性,也确保了网络将长期存在,因为最终数据只与网络一样永久。在下表中,我们可以找到代币经济学设计决策的简要总结,以及嵌入在相应设计中的通货膨胀和通货紧缩机制。
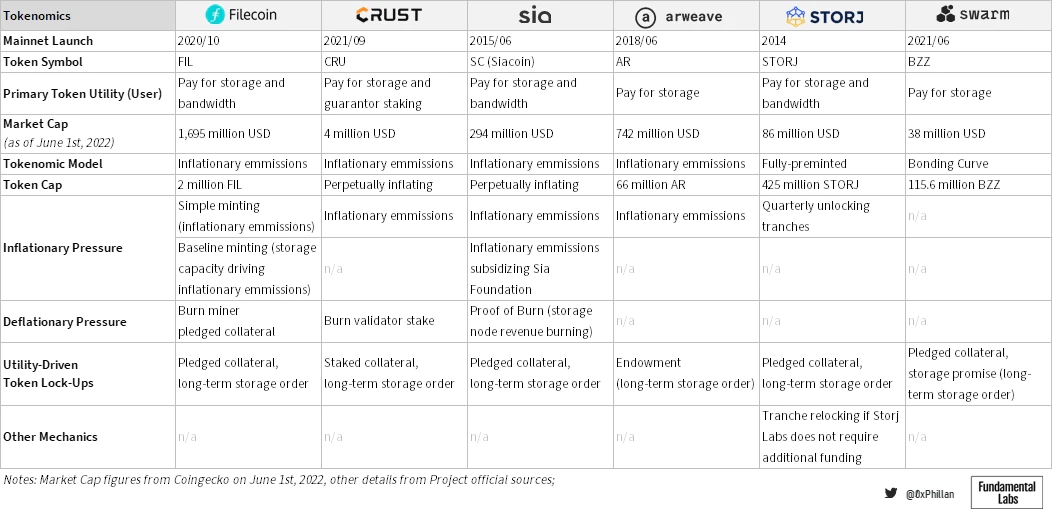
(部分存储网络的代币经济学)
哪个网络最好?
不可能说一个网络在客观上比另一个网络更好。在设计去中心化存储网络时,必须考虑无数的权衡。虽然Arweave非常适合永久存储数据,但Arweave不一定适合将Web2.0行业参与者迁移到Web3.0-并非所有数据都需要永久保存。但是,有一个强大的数据子领域确实需要永久性:NFT和dApp。
最终,设计决策是根据网络的目的做出的。
以下是各种存储网络的总结概况,它们在下面定义的一组尺度上相互比较。使用的尺度反映了这些网络的比较维度,但是应该注意的是,克服分散存储挑战的方法在许多情况下并没有好坏之分,而只是反映了设计决策。
●存储参数灵活性:用户控制文件存储参数的程度
●存储持久性:文件存储在多大程度上可以通过网络实现理论上的持久性(即无需干预)
●冗余持久性:网络通过补充或修复来保持数据冗余的能力
●数据传输激励:网络确保节点慷慨传输数据的程度
●存储跟踪的普遍性:节点之间对数据存储位置的共识程度
●有保证的数据可访问性:网络确保存储过程中的单个参与者无法删除对网络上文件的访问的能力
分数越高表明上述各项的能力越强。
Filecoin的代币经济学支持增加整个网络的存储空间,用于以不可变的方式存储大量数据。此外,他们的存储算法更适用于不太可能随时间发生很大变化的数据(冷存储)。

(Filecoin总结概况)
Crust的通证组学确保了超冗余和快速检索速度,使其适用于高流量dApp并适用于快速检索流行NFT的数据。
Crust在存储持久性方面的得分较低,因为没有持久冗余,它提供永久存储的能力会受到严重影响。尽管如此,仍然可以通过手动设置极高的复制因子来实现持久性。
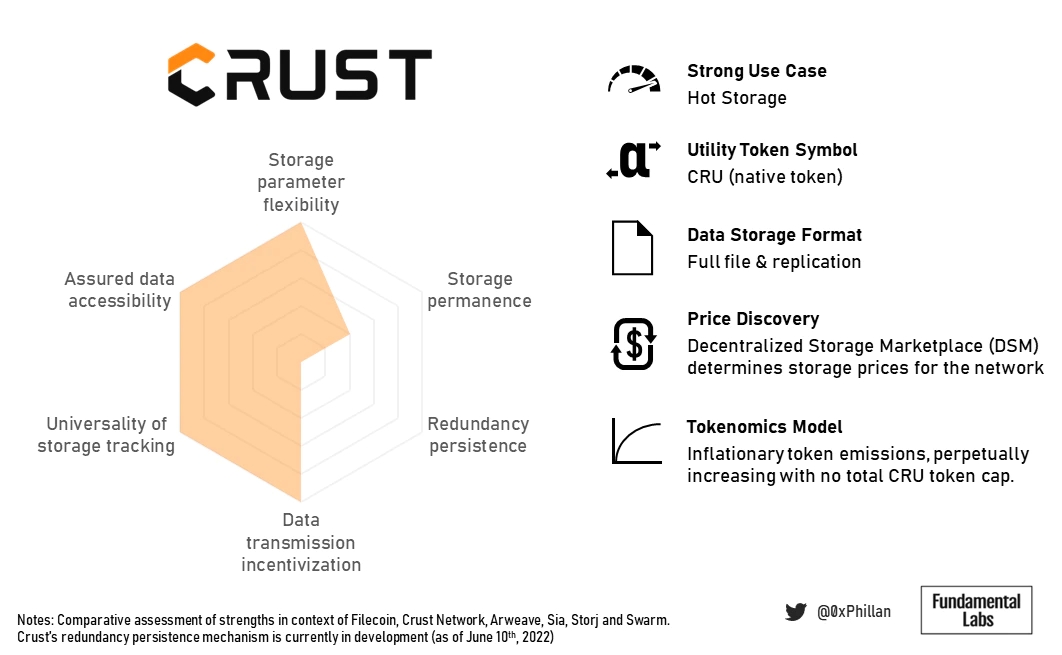
(Crust总结概况)
Sia是关于隐私的。之所以需要用户手动恢复健康,是因为节点不知道自己存储了哪些数据片段,以及这些片段属于哪些数据。只有数据所有者才能从网络中的分片中重建原始数据。
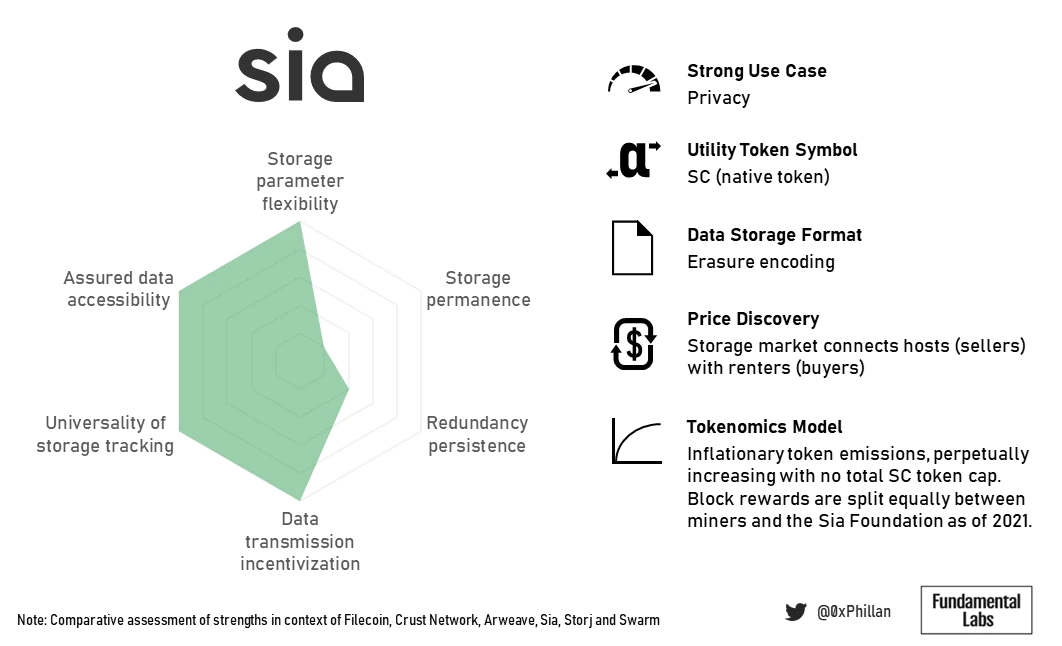
(Sia总结概况)
相比之下,Arweave是关于持久性的。这也反映在它们的禀赋设计中,这使得存储成本更高,但也使它们成为NFT存储的极具吸引力的选择。
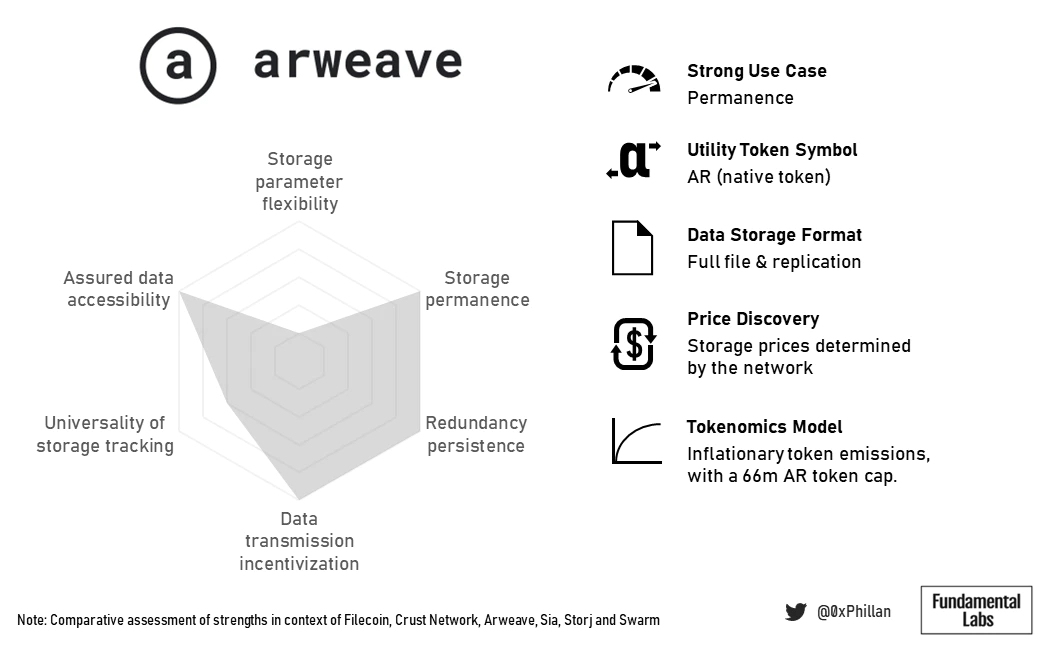
(Arweave总结概况)
Storj的商业模式似乎在很大程度上影响了他们的计费和支付方式:亚马逊AWS S3用户更熟悉按月计费。通过移除基于区块链的系统中常见的复杂支付和激励系统,Storj Labs牺牲了一些去中心化,但显着降低了AWS用户关键目标群体的进入门槛。
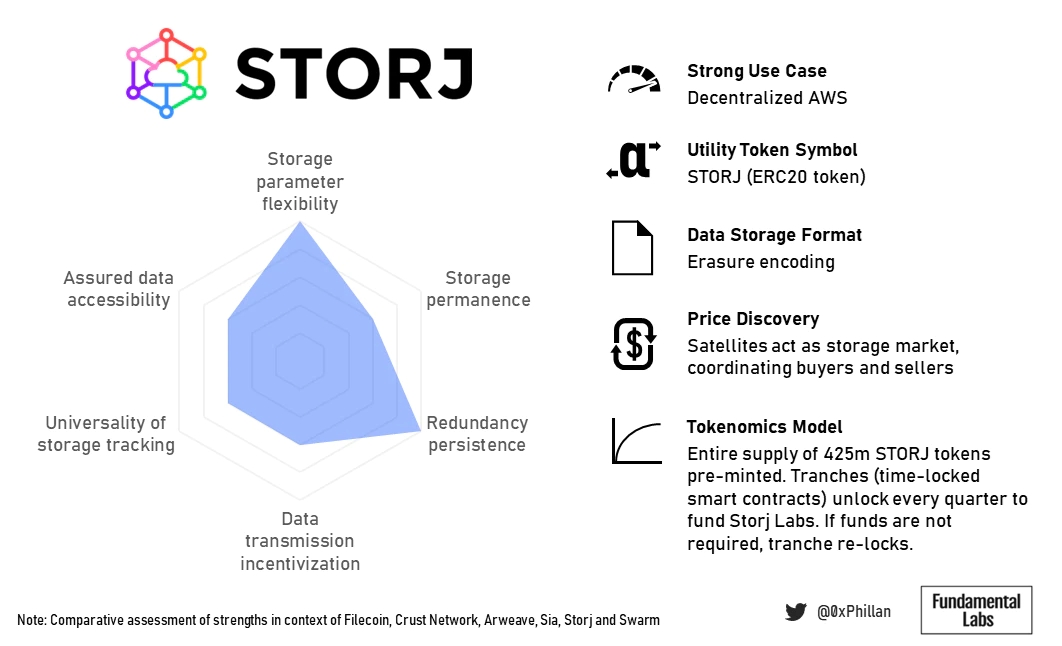
(Storj总结概况)
Swarm的联合曲线模型确保随着更多数据存储在网络上,存储成本保持相对较低的加班时间,并且它靠近以太坊区块链使其成为更复杂的基于以太坊的dApp的主要存储的有力竞争者。
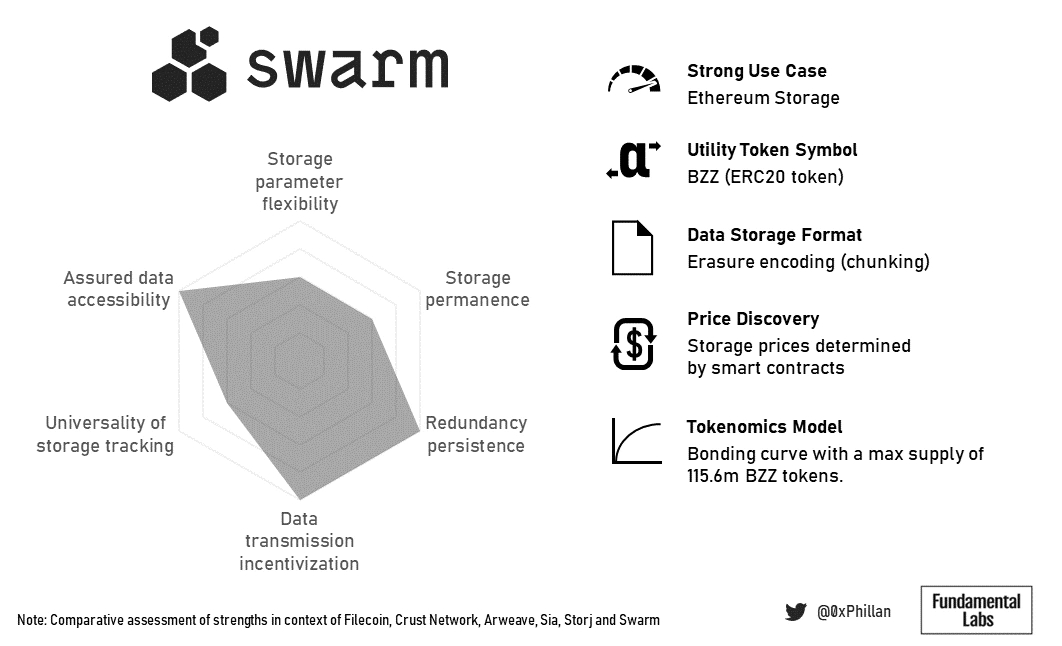
(Swarm总结概况)
对于去中心化存储网络面临的各种挑战,没有单一的最佳方法。根据网络的目的和它试图解决的问题,它必须在网络设计的技术和代币经济学方面进行权衡。网络的目的和它试图优化的特定用例将决定各种设计决策。

下一个领域
回到Web3基础设施支柱(共识、存储、计算),我们看到去中心化存储空间拥有少数强大的参与者,他们已针对特定用例将自己定位在市场中。这并不排除新网络优化现有解决方案或占领新的利基市场,但这确实提出了一个问题:下一步是什么?
答案是:计算。实现真正去中心化互联网的下一个前沿是去中心化计算。目前,只有少数解决方案能够将去信任、去中心化计算的解决方案推向市场,这些解决方案可以为复杂的dApp提供支持,这些解决方案能够以远低于在区块链上执行智能合约的成本进行更复杂的计算。
互联网计算机(ICP)和Holochain(HOLO)是在撰写本文时在去中心化计算市场中占据强势地位的网络。尽管如此,计算空间并不像共识和存储空间那样拥挤。因此,强大的竞争对手迟早会进入市场并相应地定位自己。一个这样的竞争对手是Stratos(STOS)。Stratos通过其分散式数据网格技术提供独特的网络设计。我们将去中心化计算,特别是Stratos网络的网络设计视为未来研究的领域。
Last updated